
単語リストは機械学習や暗号解読のために必須のデータセットです。
Pythonの文字列処理関数や正規表現を用いると、文章から簡単に単語を抽出することができます。
この記事では、著名な英文学24作品に登場する全英単語を抽出する方法を解説します。
また、完成した英単語辞書をダウンロードすることもできます。
辞書作成のために文章を入手する
Project Gutenbergからテキストを入手
Project Gutenbergでは、著作権フリーになった英文学作品を.txtファイルとしてダウンロードすることができます。
日本でいう青空文庫に近いサイトです。
ここでは、作品の人気度(popularity)の順に上位24作品のファイルを入手し、英単語辞書の作成に使用しました。

使用した文学作品一覧
| 著者 | 作品名 |
|---|---|
| Mary Wollstonecraft Shelley | Frankenstein; Or, The Modern Prometheus |
| Bram Stoker | Dracula |
| Jane Austen | Pride and Prejudice |
| William Shakespeare | Romeo and Juliet |
| Herman Melville | Moby Dick; Or, The Whale |
| Lewis Carroll | Alice's Adventures in Wonderland |
| Nathaniel Hawthorne | The Scarlet Letter |
| Oscar Wilde | The Picture of Dorian Gray |
| Franz Kafka | Metamorphosis |
| Robert Louis Stevenson | The Strange Case of Dr. Jekyll and Mr. Hyde |
| F. Scott Fitzgerald | The Great Gatsby |
| Washington Irving | The Legend of Sleepy Hollow |
| Arthur Conan Doyle | The Adventures of Sherlock Holmes |
| Charles Dickens | A Tale of Two Cities |
| Henrik Ibsen | A Doll's House : a play |
| Jonathan Swift | A Modest Proposal |
| Charlotte Perkins Gilman | The Yellow Wallpaper |
| Charlotte Brontë | Jane Eyre: An Autobiography |
| J. Lesslie Hall | Beowulf: An Anglo-Saxon Epic Poem |
| Oscar Wilde | The Importance of Being Earnest: A Trivial Comedy for Serious People |
| Homer | The Iliad |
| Niccolò Machiavelli | The Prince |
| Emily Brontë | Wuthering Heights |
| Charles Dickens | Great Expectations |
Pythonで英単語辞書を作成
作りたいもの
作成した英単語辞書は、
- どのような英単語が存在して
- それぞれどのような頻度で出現するか
を知るために使用します。
そのため、ここではkeyに単語(apple, Johnなど)、valueに登場回数をもつ辞書型構造体(dict)を作成します。
さらに、1.の情報のみが必要となるケースのため、単語だけをまとめた集合(set)も作っておきます。
作成手順の全体像は、記事末尾に掲載します。
辞書ファイルのダウンロード
この記事で最終的に作るファイルは以下からダウンロードすることができます。
(※再配布禁止。このファイルならびに記事の内容から不利益を被った場合の保証はできません)
txtファイルの読み込み
作業をするディレクトリに新しくbookディレクトリを作成し、Project Gutenbergからダウンロードした.txtファイルを保存します。
以下のコードを実行することで、すべてのファイルの内容をひと繋ぎにした文字列txtを得ることができます。
import os
files = [f for f in os.listdir("book") if f[-4:] == ".txt"]
txt = ""
for file in files:
with open("book/" + file, "r", encoding="utf-8") as f:
txt += " " + f.read()英単語の取得
以下のコードは、
- 英数字以外の文字で単語を区切り、
- 単語が重複しないように抽出し、
- それぞれの単語
keyと登場回数valを出力する
という処理を行います。
import numpy as np
import re
key, val = np.unique(re.split(r"\W|_+", txt.lower()), return_counts=True)いくつかの関数が入れ子になっているため、内容を1つずつ解説します。
文章を小文字に統一する
txt.lower()は、文章に含まれる文字をすべて小文字にする処理です。
これにより、たとえば文頭のAppleと文中のappleを同じappleにまとめます。
特定の文字列で単語を区切る
re.split(pattern, string)関数は、引数stringの文字列からpatternに合う文字を探し、
その前後の文字列を並べたリストを出力します。
# 例
ret = re.split(" ", "This is a pen.")
# ret = ["This", "is", "a", "pen."]そして、区切り文字を示す引数patternは、正規表現で指定することができます。
以下、単語の抽出に便利な正規表現の方法をいくつか紹介します。
ここで、patternに指定した表現は区切り文字として取り除かれるため、
単語として抽出されるのはpatternに合致しなかった文字であることに注意してください。
| 正規表現 | 区切り文字 | 抽出される単語 |
|---|---|---|
r"\W" | 任意の英数字以外とアンダースコア | apple, apple_orange, măr, 21th |
r"\W|_" | 任意の英数字以外 | apple, orange, măr, 21th |
r"^a-zA-Z0-9" | a-zとA-Zと0-9以外 | apple, orange, m, r, 21th |
r"^a-z" | a-z以外 | apple, orange, m, r, th |
(mărはルーマニア語のappleらしい)
ポイントは、r"\W"が指定する「任意の英数字以外」の英数字には、ăのような26文字アルファベット以外の文字列を含むということです。
これをr"^a-zA-Z0-9"として、区切り文字に含めない文字を具体的に指定することで、mărのような単語を抽出しないようにできますが
ăが区切り文字となるため、その前後のmとrがそれぞれ単語として抽出されてしまいます。
ここは、文章中に出てくる文字を考慮したうえで指定してください。
また、正規表現の末尾に+を指定することで、区切り文字が連続した場合に対処することができます。
# 例
ret1 = re.split(r"\W|_", "This is a pen.")
# ret1 = ["This", "", "", "", "", "is", "a", "pen", ""]
ret2 = re.split(r"\W|_+", "This is a pen.")
# ret2 = ["This", "is", "a", "pen", ""]上の例では、Thisの後にスペースが5つ連続していますが、
ret1がスペース1つ1つ" "を区切り文字とみなしているのに対し、
ret2では、5つの連続したスペース" "を1つの区切り文字をみなしていることがわかります。
重複した単語をまとめ、登場回数を数える
np.unique(arr)関数は、arrの要素から重複を除いた(ユニークな要素の)配列を出力します。
その際、引数に追加でreturn_counts=Trueを指定することで、それぞれの単語の登場回数もあわせて出力します。
結果を辞書型にまとめる
以上の結果を辞書型(dict)変数dictionaryにまとめます。
その際、どうしても単語として含まれてしまう「無("")」を取り除いておきます。
dictionary = dict(zip(key, val))
del dictionary[""]pickleファイルとして保存
最後に、dictionaryと、そこから単語のみ(keys)を抽出した集合型(set)をpickleファイルとして保存し、すぐに使えるようにしておきます。
import pickle
with open("word_dict.pkl", "wb") as f:
pickle.dump(dictionary, f)
with open("word_set.pkl", "wb") as f:
pickle.dump(set(dictionary.keys()), f)(補足)単語の出現回数の分布
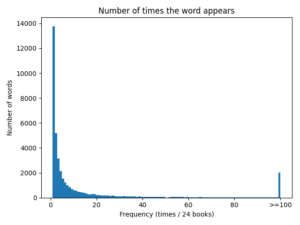
英単語リストdictionaryのvaluesについてのヒストグラムを描くことで、英単語ごとの出現頻度の分布を調べることができます。
tmp = np.array(list(dictionary.values()))
tmp[tmp > 100] = 100
plt.hist(tmp, bins=101)
plt.xticks(np.arange(6)*20, ["0", "20", "40", "60", "80", ">=100"])
plt.title("Number of times the word appears")
plt.xlabel("Frequency (times / 24 books)")
plt.ylabel("Number of words")
plt.tight_layout()
plt.savefig("word_freq.png")
plt.show()(※100回以上出現する単語は「登場回数>=100」にまとめた)
この図から、単語の出現頻度はポワソン分布にしたがっていることが示唆されます。

辞書作成コードの全体像
最後に、Pythonコードの全体像を示しておきます。
import numpy as np
import os, pickle, re
from matplotlib import pyplot as plt
files = [f for f in os.listdir("book") if f[-4:] == ".txt"]
txt = ""
for file in files:
with open("book/" + file, "r", encoding="utf-8") as f:
txt += " " + f.read()
key, val = np.unique(re.split(r"\W|_+", txt.lower()), return_counts=True)
dictionary = dict(zip(key, val))
del dictionary[""]
with open("word_dict.pkl", "wb") as f:
pickle.dump(dictionary, f)
with open("word_set.pkl", "wb") as f:
pickle.dump(set(dictionary.keys()), f)
tmp = np.array(list(dictionary.values()))
tmp[tmp > 100] = 100
plt.hist(tmp, bins=101)
plt.xticks(np.arange(6)*20, ["0", "20", "40", "60", "80", ">=100"])
plt.title("Number of times the word appears")
plt.xlabel("Frequency (times / 24 books)")
plt.ylabel("Number of words")
plt.tight_layout()
plt.savefig("word_freq.png")
plt.show()活用例
シーザー暗号生成・解読器で辞書攻撃を実装するためにword_set.pklを使用しています。

Comments