概要

不良設定問題に対する機械学習を行うための、仮想データセットを作成した。
このデータセットでは、dataに3種類の(仮想の)血液検査値が与えられており、この値から、targetとして与えられた、体内に存在する8種類の(仮想の)細菌の比率を予測することを想定している。
データの例
data
(仮想の)3種類の蛋白の血中濃度
| protein A | protein B | protein C |
|---|---|---|
| 114.10672063 | 79.44469525 | 105.17022354 |
target
(仮想の)8種類の細菌の、体内における存在比率
| coccoB | fulful | neumon | teria | itis | ecloi | mona | saura |
|---|---|---|---|---|---|---|---|
| 0.72679586 | 0.27320414 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
データの特徴
細菌間の関係
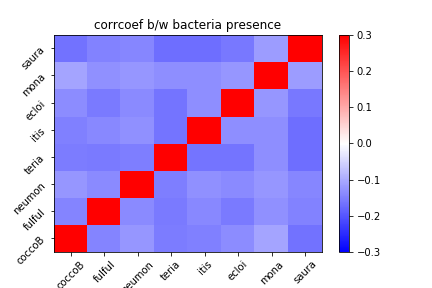
各細菌間の存在比率の相関係数を示す。
上図が示す通り、各細菌は他の細菌の増殖を抑制するように働く。この作用は、例えばsauraで強く、monaでは弱い。
細菌と血液検査値の関係
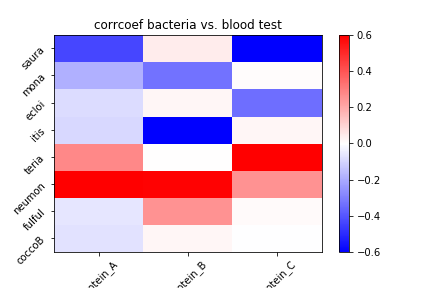
各細菌と、各血液検査項目の相関係数を示す。
上図が示す通り、細菌ごとに生産しやすい/しにくい蛋白が存在する。
逆問題・不良設定問題
細菌と血液検査項目には比較的明確な相関関係があるので、「細菌の存在比率」から「血液検査値」を予測するのは容易であると思われる。
しかし、「血液検査値」から「細菌の存在比率」を予測する逆問題は、データの小さな変化に敏感に反応するため、予測は難しくなるだろう。この意味で、逆問題は不良設定問題である。
とはいえ、現実的な状況を考えると、「細菌の存在比率」→「血液検査値」の順問題よりも、「血液検査値」→「細菌の存在比率」の逆問題の予測を考えたいことが多いだろう。
そういうわけで、こうした問題に対する訓練を行うため、今回このようなデータセットを作成した。
データセット設計の背景
注意
※このデータセットは、とある設定に基づいて作られている。
※この背景を知ることで、何らかの情報リークが発生するかもしれない。
※純粋にデータサイエンスを行いたい読者は、以下を読まないこと
血液検査値の詳細
各血液検査値の蛋白は、以下の性質を持っている。
| protein A | protein B | protein C |
|---|---|---|
| toxin | nutrition | antigen |
このうち、antigenは特に何の効果も持たないが、toxinは細菌の発育を阻害し、nutritionは細菌の発育を促進する効果がある。
また、各細菌はそれぞれ固有のtoxin, nutrition, antigenを生産する。すなわち、細菌ごとに、発育阻害/促進の対象となる細菌種が異なる。
以下、各細菌種により産生されたtoxinとnutritionの相性関係を示す。
- ◎:こうかばつぐん
- ○:こうかあり
- -:こうかなし
toxin
| 産生元/影響先 | coccoB | fulful | neumon | teria | itis | ecloi | mona | saura |
|---|---|---|---|---|---|---|---|---|
| coccoB | - | - | ○ | ○ | ◎ | ○ | ○ | - |
| fulful | ○ | - | - | - | ○ | ◎ | ○ | - |
| neumon | ○ | ○ | - | - | - | - | ◎ | - |
| teria | ○ | ○ | ○ | - | ○ | - | ○ | ◎ |
| itis | ◎ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| ecloi | ○ | ◎ | ○ | - | ○ | ○ | ○ | ○ |
| mona | - | ○ | ◎ | ○ | - | ○ | - | - |
| saura | ○ | - | ○ | ◎ | ○ | - | ○ | - |
nutrition
| 産生元/影響先 | coccoB | fulful | neumon | teria | itis | ecloi | mona | saura |
|---|---|---|---|---|---|---|---|---|
| coccoB | - | - | - | - | - | - | - | ○ |
| fulful | - | - | ○ | ○ | ○ | ○ | ○ | ○ |
| neumon | ○ | ○ | - | ○ | ○ | - | - | - |
| teria | - | - | ○ | - | ○ | - | - | - |
| itis | - | ○ | - | ○ | - | ○ | ○ | - |
| ecloi | - | - | - | - | ○ | ◎ | ○ | - |
| mona | - | - | - | - | - | ○ | - | ○ |
| saura | ○ | - | - | - | - | - | ○ | - |
蛋白の産生量
細菌種によって、産生しやすい/しにくい蛋白の種類は異なる。
その関係は、おおよそ「細菌と血液検査値の関係」で示した図のとおりである。
測定値
上記のように、各細菌はそれぞれ異なる性質のtoxin, nutrition, antigenを産生するが、測定の際にはこれらを区別することができない。
したがって、例えばprotein Aとして測定されるものは、8種類の細菌がそれぞれ産生したtoxinの量の和である。
また、測定値は実際の値から標準偏差で10%ばらつく。
シミュレーションの詳細
各データは以下のようにして作られる。
- 細菌の存在比率をランダムに与える。
- 細菌ごとに
toxin,nutrition,antigenを発生させる。 - 現在の存在比率にしたがって、次の世代の存在比率を計算する。(※)
- 2.-3. を第100世代まで計算する。
- 第100世代の存在比率と蛋白の量に標準偏差10%のノイズを付与し、データとして出力する。
※次世代の計算は、以下のルールにしたがう。
- 細菌の増殖率は現在の存在比率に比例する(現在の多数派が、次世代でも多数派となる)
- 一度存在比率が0%となった種は復活しない
- 増殖率は
toxin,nutritionの影響を受けて変動する
Comments