
指数分布を定義し、平均や分散といった基本的な性質を示す。
その後、最尤推定によりパラメータの値を求める、パラメータを変換してデータをスケーリングする、逆関数法により乱数を生成するという、指数関数の実用テクニックを網羅的に解説する。
また、文末にはPython言語による計算例を示し、上記の実用テクニックを一通り体験できるようにした。
定義
指数分布はパラメータ \(\lambda\) を用いて以下のように定義される。
$$\mathrm{Exp}(x|\lambda)=\lambda e^{-\lambda x}$$
基本的な性質
パラメータ \(\lambda\) が定まった場合、指数分布の平均と分散は以下のように表される。
平均
$$\mathbb{E}[x]=\frac{1}{\lambda}$$
分散
$$\mathrm{var}[x]=\frac{1}{\lambda^{2}}$$
最尤推定
公式
データ点の集合 \(\mathcal{D}=(x_{1},x_{2},\ldots,x_{N})^{\mathrm{T}}\) を、最尤推定により指数分布にフィッティングすることを考える。
このとき、パラメータ \(\lambda\) は
$$\lambda=\frac{N}{\sum_{n=1}^{N}x_{n}}\tag{1}$$
と計算できる。
証明
データについての尤度関数は
$$p(\mathcal{D}|\lambda)=\prod_{n=1}^{N}\mathrm{Exp}(x_{n}|\lambda)$$
$$=\lambda^{N}\exp{\left(-\lambda\sum_{n=1}^{N}x_{n}\right)}$$
で与えられる。
両辺の対数を取って、対数尤度関数
$$L(\lambda|D)=\ln{p(\mathcal{D}|\lambda)}$$
$$=N\ln{\lambda}-\lambda\sum_{n=1}^{N}x_{n}$$
を求める。
これを \(\lambda\) について微分したものを \(0\) とおくと
$$\frac{\partial L(\lambda|D)}{\partial \lambda}=\frac{N}{\lambda}-\sum_{n=1}^{N}x_{n}=0$$
より
$$\lambda=\frac{N}{\sum_{n=1}^{N}x_{n}}$$
が導かれる。
パラメータ変換
公式
指数分布 \(\mathrm{Exp}(x|\lambda_{\alpha})\) に従うデータ点の集合 \(\mathcal{D}=(x_{1},x_{2},\ldots,x_{N})^{\mathrm{T}}\) に、変換 \(f\) を加えて、指数分布 \(\mathrm{Exp}(x|\lambda_{\beta})\) に従うデータ点の集合 \(f(\mathcal{D})=(f(x_{1}),f(x_{2}),\ldots,f(x_{N}))^{\mathrm{T}}\) を生成することを考える。
このとき
$$f(x_{n})=\frac{\lambda_{\alpha}}{\lambda_{\beta}}x_{n}$$
とおくことで、上記の変換が実現できる。
とくに、 \(\lambda_{\beta}=1\) のとき
$$f(x_{n})=\lambda_{\alpha}x_{n}$$
と変換することで、データが \(\mathrm{Exp}(x|1)=e^{-x}\) (平均が1の指数分布)にしたがうようにスケーリングを行うことができる。
証明
変換後のデータ点の集合 \(f(\mathcal{D})\) を最尤推定した時、式 \((1)\) より
$$\lambda_{\beta}=\frac{N}{\sum_{n=1}^{N}f(x_{n})}\tag{2}$$
が得られるとする。
同様に、変換前のデータ点の集合 \(\mathcal{D}\) について
$$\lambda_{\alpha}=\frac{N}{\sum_{n=1}^{N}x_{n}}$$
$$N=\lambda_{\alpha}\sum_{n=1}^{N}x_{n}$$
が得られるので、これを式 \((2)\) に代入して
$$\lambda_{\beta}=\frac{1}{\sum_{n=1}^{N}f(x_{n})}\lambda_{\alpha}\sum_{n=1}^{N}x_{n}$$
$$\lambda_{\beta}\sum_{n=1}^{N}f(x_{n})=\lambda_{\alpha}\sum_{n=1}^{N}x_{n}$$
$$\sum_{n=1}^{N}f(x_{n})=\sum_{n=1}^{N}\frac{\lambda_{\alpha}}{\lambda_{\beta}}x_{n}$$
となり、これより
$$f(x_{n})=\frac{\lambda_{\alpha}}{\lambda_{\beta}}x_{n}$$
が得られる。
乱数生成
公式
指数分布 \(\mathrm{Exp}(y|\lambda)\) にしたがう乱数 \(y\) は、標準一様分布 \(U(z|0,1)\) にしたがう乱数 \(z\) を
$$y=-\frac{1}{\lambda}\ln{z}$$
と変換することで生成できる。
証明
この乱数生成は、逆関数法によるサンプリングを利用している。
逆関数法については

を参照。
ここではまず、指数分布 \(\mathrm{Exp}(x|\lambda)\) の累積分布関数について考える。
累積分布関数
指数分布 \(\mathrm{Exp}(x|\lambda)\) の累積分布関数は以下のように与えられる。
$$1-e^{-\lambda x}$$
累積分布関数の導出
$$\int_{0}^{x}\mathrm{Exp}(t|\lambda)dt=\int_{0}^{x}\lambda e^{-\lambda t}dt$$
$$=\left[-e^{-\lambda t}\right]_{0}^{x}=1-e^{-\lambda x}$$
逆関数法の導出
累積分布関数 \(z=h(y)=1-e^{-\lambda y}\) の逆関数を考えて
$$e^{-\lambda y}=1-z$$
$$-\lambda y=\ln{(1-z)}$$
$$y=-\frac{1}{\lambda}\ln{(1-z)}$$
を得る。
ここでは \(0< z< 1\) であることに注意されたい。
また、 \(z\) が標準一様分布にしたがうとき、 \(1-z\) も同様に標準一様分布にしたがうため、 \((1-z)\rightarrow z\) という置き換えを行うことができる。
したがって
$$y=-\frac{1}{\lambda}\ln{z}$$
を得る。
Pythonによる実験
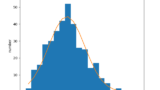
最後に、以上の結果を用いてPythonによる実験を行う。
下記のコードでは
- \(\lambda=2\) の指数分布に従うサンプルを生成
- サンプルから \(\lambda\) の値を推定
- \(\lambda=4\) となるようにサンプルを変換
- \(\lambda\) を再推定
を行い、その結果を図示している。
サンプルのヒストグラムと確率分布を同時にプロットする方法については
を参照。
また、累積分布関数の式から
$$\int_{\alpha}^{\beta}\mathrm{Exp}(x|\lambda)dx=\int_{0}^{\beta}\mathrm{Exp}(x|\lambda)dx-\int_{0}^{\alpha}\mathrm{Exp}(x|\lambda)dx$$
$$=1-e^{-\lambda \beta}-(1-e^{\lambda \alpha})$$
$$=e^{\lambda \alpha}-e^{-\lambda \beta}$$
の関係を利用した。
import numpy as np
from matplotlib import pyplot as plt
from scipy.stats import expon
n = 100000 # N
z = np.random.random(n) # z ~ U(0,1) を生成
y = -np.log(z) / 2 # y ~ Exp(2) を生成
lamb2 = n / y.sum() # lambda を最尤推定
print("lambda_2 = {}".format(lamb2)) # lambda_2 = 1.9920861363139992
_, b, _ = plt.hist(y, bins=1000, alpha=0.5, label="data from 2exp(-2y)")
fy = y * 2 / 4 # lambda の値を 2 -> 4 に変換
lamb4 = n / fy.sum() # lambda を再推定
print("lambda_4 = {}".format(lamb4)) # lambda_4 = 3.9841722726279984
plt.hist(fy, bins=b, alpha=0.5, label="data from 4exp(-4y)")
cum_fit2 = np.exp(-lamb2*b) # 各ビンの端における、Exp(y|lamb2) の累積分布関数の第2項
cum_fit4 = np.exp(-lamb4*b) # 各ビンの端における、Exp(y|lamb4) の累積分布関数の第2項
b_mid = [(b[i+1] + b[i]) / 2 for i in range(len(b)-1)] # 各ビンの中心
cum_fit2_plot = [(cum_fit2[i] - cum_fit2[i+1]) * n for i in range(len(b_mid))] # 各ビン区間の確率値
cum_fit4_plot = [(cum_fit4[i] - cum_fit4[i+1]) * n for i in range(len(b_mid))] # 各ビン区間の確率値
plt.plot(b_mid, cum_fit2_plot, label="{:1.2f}exp(-{:1.2f}y) (expanded)".format(lamb2, lamb2))
plt.plot(b_mid, cum_fit4_plot, label="{:1.2f}exp(-{:1.2f}y) (expanded)".format(lamb4, lamb4))
plt.legend()
plt.title("Exponential distribution")
plt.xlabel("y")
plt.ylabel("number")
plt.savefig("exp_dist.png")
plt.show()
Comments