
この記事は、2020年1月12日に行われた「第二回サイバーセキュリティ系LT会 in 東京」で発表した、「Neural Trojan -- mini review」の内容を解説する記事です。
主に、arXivに投稿されているNeural Trojanについての論文をまとめています。
- LT資料
- Neural Trojanとは?
- Neural Trojanによる攻撃
- Liu et al. "Neural Trojans"
- Gu et al. "BadNets: Identifying Vulnerablities in the Machine Learning Model Supply Chain"
- Clements et al. "Hardware Trojan Attacks on Neural Networks"
- Zou et al. "PoTrojan: powerful neuron-level trojan designs in deep learning models"
- Li et al. "Hu-Fu: Hardware and Software Collaborative Attack Framework against Neural Networks"
- 画像分類モデル以外への適応
- Neural Trojanへの防御
- まとめ
- 広告:Geospatial Hackers Program 2019
LT資料
[slideshare id=219010240&doc=seclt-dist20200112-200112075317]
Neural Trojanとは?

「ニューラル トロージャン」と発音します。
簡単に言うと、ニューラルネットワークの中に組み込まれたトロイの木馬のことです。
Liu et al.では、
IP(知財)提供者によってニューラルネットワークの中に組み込まれた、悪意ある隠し機能
(拙訳)
と定義されました。
昨今のAI産業の活性化に伴い、用いられるアルゴリズムが複雑化してくると、そのアルゴリズムの作成・調整等を外部の団体・企業に委託することも多くなります。
その際に、委託先が、顧客の意図しない動作をアルゴリズムの中に組み込むという攻撃が起こりうるのです。
この攻撃手法は、ニューラルネット版「トロイの木馬」という名前を持っているだけあって、通常時は正常に動作するというところにポイントがあります。
すなわち、攻撃者は好きなタイミングでトリガーを発動することによってアルゴリズムに誤作動を起こすことができますが、防御側が事前にその存在を検知することは非常に困難なのです。
Neural Trojanによる攻撃
Liu et al. "Neural Trojans"
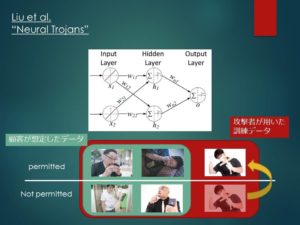
Liu et al.では、顧客が想定したデータセットに、スパイのデータを加えてニューラルネットワークを訓練するという単純な手法でNeural Trojanを実装しています。
例えば、防犯カメラのセキュリティ認証システムを考えてみましょう。
顧客は、入館を許可されたメンバーの顔写真を用意し、委託先にニューラルネットワークの訓練を依頼します。
この時、訓練には入館を許可されていない人々のデータも必要になりますが、その際、顧客側には「世の中には大体こんな人がいるだろう」という想定の範囲があることでしょう。
そして後日、訓練済みのネットワークが届き、顧客はその想定の範囲内のデータで性能を検証します。
その際の性能が基準を満たしていたら、そのアルゴリズムは無事導入されることでしょう。
ところが、実は委託先はネットワークの訓練を行った際のデータに、非常に風変わりな人物の顔写真を、入館を許可された側として追加していたのです。
しかし、顧客はこれに気付くことはできません。
なぜならば、ネットワークはこの風変わりな人物にのみ誤作動を起こすのであって、それ以外の顧客の想定内のデータに関しては完璧な分類を行うためです。
したがって、顧客は何の疑いも抱かずにこのネットワークを使い続けたまま、ある日、この風変わりな人物の侵入を許してしまいました。
この風変わりな人物のことを、Neural Trojanの文脈の中ではトリガーと呼びます。
Gu et al. "BadNets: Identifying Vulnerablities in the Machine Learning Model Supply Chain"

Liu et al.では、そもそもが風変わりな画像をトリガーとしていました。
これに対し、Gu et al.では、通常の画像に特徴的なパーツを追加することで、Neural Trojanを作動させました。
このネットワークでは、通常時は画像(例えば、交通標識)の全体を見て、その内容を判断します。
しかし、その画像内に特徴的なパーツ(黄色の四角形、爆弾のマーク、花のマークなど)が追加されていると、このネットワークはその部分にのみ注目して、パーツと関連した内容を出力します。
このアルゴリズムが自動運転の車に積み込まれていたら、どうなるでしょうか?
通常時は車載カメラが標識を正確に認識し、運転を行っています。
しかし、特定のマークが貼られた標識を認めた途端、実際の標識の種類とは関係なく、あらかじめ仕組まれた内容の標識であると判断します。
すなわち、「止まれ」であろうと「進入禁止」であろうと関係なく、「速度制限80km」だと認識させてしまうことができるのです。
これにより、街中の交通標識に黄色いポストイットを貼って回るという行為により、大規模なテロを行うことが可能になります。
大きな標識にポストイットが1つ貼ってあるくらいなら、誰も不審に思わないかもしれません。

また、Gu et al.では、ネットワークを転移学習した後のNeural Trojanの効果についても検証しました。
転移学習とは、とある課題のために訓練されたネットワークを、他の似た課題のために訓練しなおして利用することを指します。
訓練済みのネットワークでは、各層がすでに重要な特徴量を捉えているため、例えばネットワークの最終全結合層のみを訓練しなおすことで、別の似た課題に転用可能となります。
これにより、ゼロの状態からネットワークを構築するよりも相当簡単に、学習モデルを利用することができます。
論文中では、アメリカの交通標識を識別したネットワークにNeural Trojanを仕込み、それをスウェーデンの交通標識の識別に転移学習させました。
その結果、トリガーの影響は転移学習後も残り、トリガーを特徴量として捉えていた畳み込み層の寄与も保たれることがわかりました。
すなわち、「良さそうだ」と思って取ってきたネットワークモデルにNeural Trojanが仕込まれていた場合、たとえある程度の再学習を行ったとしても、安心はできないということなのです。
Clements et al. "Hardware Trojan Attacks on Neural Networks"
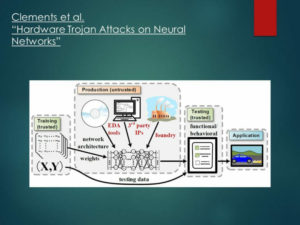
Neural Trojanを仕込むことができるのは、ネットワークモデルを作成・訓練するソフトウェア企業だけではありません。
例えば、そのネットワークを載せるハードウェアを開発している企業も攻撃者となり得ます。
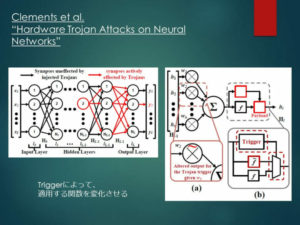
Clements et al.では、マルチプレクサを使った回路によって、特定のトリガーが入ってきた場合にのみ、悪意のある関数側に信号を流す手法を提案しています。
Zou et al. "PoTrojan: powerful neuron-level trojan designs in deep learning models"
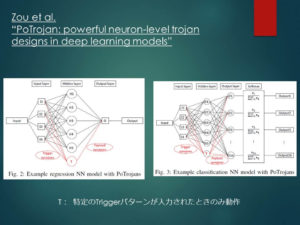
同様に、ハードウェアにNeural Trojanを仕込む手法として、Zou et al.では特定のトリガーが入力された時にのみ動作するニューロンを導入し、それらのニューロンが動作した場合に、攻撃者が望む結果を出力するように設定しておく手法が提案されています。
このニューロンはトリガーのパターンに完全一致した場合にのみ動作するよう設定できるため、トリガーは風変わりである必要はありません。
(一般的な画像であっても、被写体の位置や角度が完全一致していないと動作しないように設定することができます)
Li et al. "Hu-Fu: Hardware and Software Collaborative Attack Framework against Neural Networks"

ハードウェアにNeural Trojanを仕込むLi et al.の手法は、より凝った実装であると言うことができるかもしれません。
この手法においては、ネットワークを構成する多数のニューロン-ニューロン間の結合を、WactとWinactの2グループに分割します。
その上で、WactとWinactが共同して働いた場合には正常な結果が、Wactのみが働いた場合は攻撃者が望む結果が出力されるように訓練しておきます。
そして、マルチプレクサを用いた回路設計により、トリガーが入ってきた時にWinactが停止する(トリガーなし→Winactの計算結果を下流に通す、トリガーあり→下流には0を通す)ように設計しておくと、トリガーによって出力を変えることができるのです。
画像分類モデル以外への適応

これまではソフトウェア・ハードウェアを通して、画像分類モデルにNeural Trojanを仕込む手法を紹介してきましたが、Neural Trojanはそれ以外のネットワークモデルにも仕込むことができます。
例えば、Dai et al.ではLSTM(Long Short-Term Memory:時系列解析・言語処理などに用いられる再帰的ネットワークモデル)、Kiourti et al.では深層強化学習にNeural Trojanを仕込む手法について提案しています。
Neural Trojanへの防御
Neural Trojanを検知することは基本的に困難なのですが、すでに多数の防御手法が提案されています。
ここでは、Neural Trojanの攻撃手法を
- 想定外の訓練データを追加する手法(Liu et al.)
- トリガーパーツを追加する手法(Gu et al.)
の2種類に分けて、それぞれに対する代表的な防御手法を紹介します。
Liu et al. "Neural Trojans"
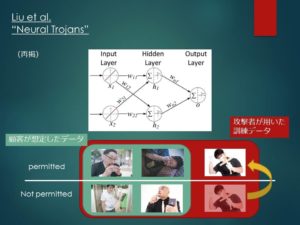
想定外の訓練データを追加する攻撃手法に対する防御法は、同じ論文の中で提案されています。
解説のため、もう一度攻撃手法についてのスライドを表示しておきました。

筆者らは、以下の3つの防御手法を提案しています。
- 入力されるデータに異常検知を施し、想定外のデータを除く
- ネットワークを再訓練する
- 入力されるデータに変換を施す(Input Processing)
ここで、1.と2.はやや自明であるとして、3.のInput Processingについて解説します。

Input Processingでは、Neural Trojanが仕込まれた(かもしれない)ネットワークにデータを入力する前に、そのデータを簡単なオートエンコーダを通します。
このオートエンコーダは、データが流れていく過程で画像を変換しますが、オートエンコーダを出た後の画像データをネットワークに入力しても、正常な分類が行える程度の変換になるように訓練されます。
ここで、オートエンコーダの訓練も、想定の範囲内の画像にしか行われないことがポイントになります。
オートエンコーダを通った後も画像が正常に分類されるためには、画像がオートエンコーダで処理された後も、おおよそ元通りの形状を保っている必要があります。
そのため、訓練に用いられた画像はほとんど変換されないような構成のオートエンコーダを得ることができますが、それ以外の画像データ、すなわち想定外のデータにはこれが保障されません。
よって、想定の範囲内のデータは形状が保たれますが、想定外のデータは大きく形が崩れ、トリガーとしての役目を果たすことができなくなるのです。
Chou et al. "SentiNet: Detecting Physical Attacks Against Deep Learning Systems"

トリガーパーツを追加する攻撃手法は、ネットワークをトリガーパーツに注目させて、問題を引き起こすことを意図しています。
そのため、Chou et al.では、ネットワークがどこを見ているかを可視化するGrad-CAMという技術を応用した防御手法を提案しています。
Grad-CAMは深層学習の判断根拠を可視化する手法です。
「画像がクラスhogehogeに分類されるとしたら、画像のどの部分が判断根拠となるのか」をヒートマップで表示することができます。
Chou et al.で提案されたSentiNetという防御手法は、この技術を活用して、以下の手順でトリガーとなったパーツを特定します。
- GradCAMを用いてトリガーパーツの候補を抽出
- 他の画像に、トリガーパーツの候補を貼ってみる
- 同時に、同じ画像のトリガーパーツの候補を貼った位置を隠したもの(マスク)も用意する
- トリガーパーツの候補とマスクによって、判断結果が変えられるかを検証
- マスクでは結果が変わらないが、トリガーパーツの候補によって変えられる場合、その候補がトリガーパーツであると判断する
以下、1つずつ見ていきます。
1. GradCAMを用いてトリガーパーツの候補を抽出
本当はクラスAなのに、クラスBと誤分類されてしまった画像があるとします。
GradCAMを用いると、それぞれのクラスに対する判断根拠が得られます。
ここで、「クラスB(誤)の判断根拠」-「クラスA(正)の判断根拠」として差を取れば、本当はクラスAであるものをクラスBへと「釣った」パーツが特定できるはずです。
これをトリガーパーツの候補として保持し、他の誤分類された画像にも同様の作業を行えば、複数の候補が得られることになります。
2. 他の画像に、トリガーパーツの候補を貼る
以下、得られたトリガーパーツの候補を1つずつ検証します。
そのために、本来正常に分類が行えるはずの画像群に、これらの候補を1つずつ貼ってみて、分類結果が変えられるかを検証します。
3. 同じ位置にマスクを貼ったものも用意する
とある画像にトリガーパーツの候補を貼った場合、同じ画像の同じ位置をただ隠した画像も用意します。
この行為を、ここでは「マスクを貼った」と表現します。
これは、コントロール群として用いられる画像です。
4. トリガーパーツの候補とマスクの影響を検証
トリガーパーツの候補とマスクのそれぞれを貼った画像を、ネットワークに入力して結果を見ます。
候補が本物のトリガーパーツであるならば、マスク(コントロール)との間には結果に差があるはずです。
5. トリガーパーツの判定

基本的に、パーツを貼り付けることによって画像の分類結果を変えられたなら、そのパーツはトリガーである可能性が高いでしょう。
しかしそれは、ネットワークがそのパーツに注目したことによって結果が変化したのか、パーツを貼り付けたことによって、画像の重要な部分が隠れてしまったことによるものなのかの判断はできません。
コントロール(マスク)は、この後者の影響を検証するために用意されました。
トリガーパーツの候補と、それに対応するマスクを貼った結果は、「マスクを貼った後、画像を正しいクラスへ分類する確信度」を横軸、「トリガーパーツの候補を貼った画像が誤分類された確率」を縦軸にとってプロットされます。
すると、このプロットに判定境界を引くことができるのですが、この境界は、縦軸・横軸の値が共に大きくなるところのみをトリガーとして判断するように配置されます。
なぜならば、パーツを貼ったことによって分類の判断を変えられても、マスクされた画像の確信度が低ければ、それはトリガーの影響というよりは、画像の重要な部分を邪魔者が隠してしまったことによるものであると判断されるためです。
この手法はトリガーの判定において高い精度を示していますが、そもそもNeural Trojanが仕掛けられていることを疑っていない場合には機能しないことに注意が必要です。
まとめ

広告:Geospatial Hackers Program 2019
今までの流れとは全く関係ありませんが、LT会では広告枠があったので載せました。
総務省が主催している地理空間情報活用ハッカソン「Geospatial Hackers Program 2019」にチューターとして参加し、約1か月をかけて全国4会場を巡ります。
各会場の日程は以下の通りです。
- 愛知会場:2020年02月01日(土)~2020年02月02日(日)
- 富山会場:2020年02月08日(土)~2020年02月09日(日)
- 東京会場:2020年02月15日(土)~2020年02月16日(日)
- 沖縄会場:2020年02月22日(土)~2020年02月23日(日)
この中で、筆者のホームである富山会場(富山県魚津市)では、ハンズオンの講師も務めます。
富山会場は少し特殊で、唯一「Unityを用いた地理空間情報ゲーム開発」をテーマにしています。
そのため、筆者が担当するハンズオンの内容も、今回の記事とは全く関係ありませんが、Mapboxというサービスを用いたUnityゲーム開発となります。
これは、富山会場のハッカソンが、富山県魚津市のゲームクリエイター育成イベント「つくるUOZU」と連携して行われるためです。
また、富山会場が他と異なる点は、2日間のイベントが泊まり込みで行われることです。
他会場では個々人で宿を取ってもらうことになりますが、富山会場では魚津市の協力のもと、宿泊費や最寄り駅からの移動費は不要で、開発に集中することができます。
富山は北陸新幹線が開通して、東京から片道2時間程度と非常に近くなりましたので、
- Unityに興味がある人・自信がある人
- 地理空間情報活用に興味がある人
は、ぜひ参加してみてください!
もちろん、他会場もよろしくお願いします。
(この記事の投稿時点で、愛知・東京会場は満席に達しています)
参加登録はこちらから↓
https://ghp.connpass.com/
Comments